#sql cte
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
Updating SQL Server Tables Using SELECT Statements: Techniques and Examples
To perform an UPDATE from a SELECT in SQL Server, you typically use a subquery or a common table expression (CTE) to select the data that you want to use for the update. There are a few different approaches you can take depending on your specific requirements. Here are some examples: Using Subquery If you want to update a table based on values from another table, you can use a subquery in your…
View On WordPress
0 notes
Text
the bad news: I cannot use the tool for this specific use case out of the box, need to do some setup work first
the good news: while doing the setup work, I realized I… don’t actually need the tool. The answer was staring me in the face all this time!
…wait.
I have a tool that is literally built for catching inconsistencies across databases
WHY WASNT I USING IT????
#ctes I’m sorry I ever doubted you T_T#I got so caught up in testing this out I left work an hour late oops#I hope the coworker inrecruited to help me verify things has time tomorrow because I want to know if I got it right this time ;w;#also I named the sql file ‘epiphany’#don't mind me having a moment
3 notes
·
View notes
Text
the guy who had my position before me LOVED using temp tables to the point that if he needed to pull four values from one table he set up four nearly identical temp tables that just had different filters in their WHERE clause and then joined their results. I don't know enough to know if this is normal but for sure this shit drives me crazy cause he never used a single CTE, instead nesting queries 4 or 5 deep, and remaking these reports so the sql is readable takes too much time.
21 notes
·
View notes
Text
Master SQL for Data Analysis Online Course with Gritty Tech
In today’s data-driven world, mastering SQL is no longer optional for anyone serious about a career in data. Whether you're an aspiring data analyst, business intelligence professional, or looking to enhance your analytical toolkit, enrolling in a comprehensive SQL for data analysis online course is one of the best decisions you can make. At Gritty Tech, we offer top-tier, affordable SQL courses tailored to modern industry demands, guided by expert tutors with global experience For More...
Why Choose Gritty Tech for Your SQL for Data Analysis Online Course?
Choosing the right platform to study SQL can be the difference between just watching videos and truly learning. Gritty Tech ensures learners gain practical, industry-aligned skills with our expertly crafted SQL for data analysis online course.
Gritty Tech’s course is curated by professionals with real-world experience in SQL and data analytics. We emphasize building conceptual foundations, practical applications, and project-based learning to develop real analytical skills.
Education should be accessible. That’s why we offer our SQL for data analysis online course at budget-friendly prices. Learners can choose from monthly plans or pay per session, making it easier to invest in your career without financial pressure.
Our global team spans 110+ countries, bringing diverse insights and cross-industry experience to your learning. Every instructor in the SQL for data analysis online course is vetted for technical expertise and teaching capability.
Your satisfaction matters. If you’re not happy with a session or instructor, we provide a smooth tutor replacement option. Not satisfied? Take advantage of our no-hassle refund policy for a risk-free learning experience.
What You’ll Learn in Our SQL for Data Analysis Online Course
Our course structure is tailored for both beginners and professionals looking to refresh or upgrade their SQL skills. Here’s what you can expect:
Core concepts include SELECT statements, filtering data with WHERE, sorting using ORDER BY, aggregations with GROUP BY, and working with JOINs to combine data from multiple tables.
You’ll move on to intermediate and advanced topics such as subqueries and nested queries, Common Table Expressions (CTEs), window functions and advanced aggregations, query optimization techniques, and data transformation for dashboards and business intelligence tools.
We integrate hands-on projects into the course so students can apply SQL in real scenarios. By the end of the SQL for data analysis online course, you will have a portfolio of projects that demonstrate your analytical skills.
Who Should Take This SQL for Data Analysis Online Course?
Our SQL for data analysis online course is designed for aspiring data analysts and scientists, business analysts, operations managers, students and job seekers in the tech and business field, and working professionals transitioning to data roles.
Whether you're from finance, marketing, healthcare, or logistics, SQL is essential to extract insights from large datasets.
Benefits of Learning SQL for Data Analysis with Gritty Tech
Our curriculum is aligned with industry expectations. You won't just learn theory—you'll gain skills that employers look for in interviews and on the job.
Whether you prefer to learn at your own pace or interact in real time with tutors, we’ve got you covered. Our SQL for data analysis online course offers recorded content, live mentorship sessions, and regular assessments.
Showcase your achievement with a verifiable certificate that can be shared on your resume and LinkedIn profile.
Once you enroll, you get lifetime access to course materials, project resources, and future updates—making it a lasting investment.
Additional Related Keywords for Broader Reach
To enhance your visibility and organic ranking, we also integrate semantic keywords naturally within the content, such as:
Learn SQL for analytics
Best SQL online training
Data analyst SQL course
SQL tutorials for data analysis
Practical SQL course online
Frequently Asked Questions (FAQs)
What is the best SQL for data analysis online course for beginners? Our SQL for data analysis online course at Gritty Tech is ideal for beginners. It covers foundational to advanced topics with hands-on projects to build confidence.
Can I learn SQL for data analysis online course without prior coding experience? Yes. Gritty Tech’s course starts from the basics and is designed for learners without any prior coding knowledge.
How long does it take to complete a SQL for data analysis online course? On average, learners complete our SQL for data analysis online course in 4-6 weeks, depending on their pace and chosen learning mode.
Is certification included in the SQL for data analysis online course? Yes. Upon successful completion, you receive a digital certificate to showcase your SQL proficiency.
How does Gritty Tech support learners during the SQL for data analysis online course? Our learners get access to live mentorship, community discussions, Q&A sessions, and personal feedback from experienced tutors.
What makes Gritty Tech’s SQL for data analysis online course different? Besides expert instructors and practical curriculum, Gritty Tech offers flexible payments, refund options, and global teaching support that sets us apart.
Can I use SQL for data analysis in Excel or Google Sheets? Absolutely. The skills from our SQL for data analysis online course can be applied in tools like Excel, Google Sheets, Tableau, Power BI, and more.
Is Gritty Tech’s SQL for data analysis online course suitable for job preparation? Yes, it includes job-focused assignments, SQL interview prep, and real-world business case projects to prepare you for technical roles.
Does Gritty Tech offer tutor replacement during the SQL for data analysis online course? Yes. If you’re unsatisfied, you can request a new tutor without extra charges—ensuring your comfort and learning quality.
Are there any live classes in the SQL for data analysis online course? Yes, learners can choose live one-on-one sessions or join scheduled mentor-led sessions based on their availability.
Conclusion
If you're serious about launching or accelerating your career in data analytics, Gritty Tech’s SQL for data analysis online course is your gateway. With a commitment to high-quality education, professional support, and affordable learning, we ensure that every learner has the tools to succeed. From flexible plans to real-world projects, this is more than a course—it’s your step toward becoming a confident, data-savvy professional.
Let Gritty Tech help you master SQL and take your data career to the next level.
0 notes
Text
This SQL Trick Cut My Query Time by 80%
How One Simple Change Supercharged My Database Performance
If you work with SQL, you’ve probably spent hours trying to optimize slow-running queries — tweaking joins, rewriting subqueries, or even questioning your career choices. I’ve been there. But recently, I discovered a deceptively simple trick that cut my query time by 80%, and I wish I had known it sooner.

Here’s the full breakdown of the trick, how it works, and how you can apply it right now.
🧠 The Problem: Slow Query in a Large Dataset
I was working with a PostgreSQL database containing millions of records. The goal was to generate monthly reports from a transactions table joined with users and products. My query took over 35 seconds to return, and performance got worse as the data grew.
Here’s a simplified version of the original query:
sql
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
transactions t
JOIN
users u ON t.user_id = u.user_id
WHERE
t.created_at >= '2024-01-01'
AND t.created_at < '2024-02-01'
GROUP BY
u.user_id, http://u.name;
No complex logic. But still painfully slow.
⚡ The Trick: Use a CTE to Pre-Filter Before the Join
The major inefficiency here? The join was happening before the filtering. Even though we were only interested in one month’s data, the database had to scan and join millions of rows first — then apply the WHERE clause.
✅ Solution: Filter early using a CTE (Common Table Expression)
Here’s the optimized version:
sql
WITH filtered_transactions AS (
SELECT *
FROM transactions
WHERE created_at >= '2024-01-01'
AND created_at < '2024-02-01'
)
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
filtered_transactions t
JOIN
users u ON t.user_id = u.user_id
GROUP BY
u.user_id, http://u.name;
Result: Query time dropped from 35 seconds to just 7 seconds.
That’s an 80% improvement — with no hardware changes or indexing.
🧩 Why This Works
Databases (especially PostgreSQL and MySQL) optimize join order internally, but sometimes they fail to push filters deep into the query plan.
By isolating the filtered dataset before the join, you:
Reduce the number of rows being joined
Shrink the working memory needed for the query
Speed up sorting, grouping, and aggregation
This technique is especially effective when:
You’re working with time-series data
Joins involve large or denormalized tables
Filters eliminate a large portion of rows
🔍 Bonus Optimization: Add Indexes on Filtered Columns
To make this trick even more effective, add an index on created_at in the transactions table:
sql
CREATE INDEX idx_transactions_created_at ON transactions(created_at);
This allows the database to quickly locate rows for the date range, making the CTE filter lightning-fast.
🛠 When Not to Use This
While this trick is powerful, it’s not always ideal. Avoid it when:
Your filter is trivial (e.g., matches 99% of rows)
The CTE becomes more complex than the base query
Your database’s planner is already optimizing joins well (check the EXPLAIN plan)
🧾 Final Takeaway
You don’t need exotic query tuning or complex indexing strategies to speed up SQL performance. Sometimes, just changing the order of operations — like filtering before joining — is enough to make your query fly.
“Think like the database. The less work you give it, the faster it moves.”
If your SQL queries are running slow, try this CTE filtering trick before diving into advanced optimization. It might just save your day — or your job.
Would you like this as a Medium post, technical blog entry, or email tutorial series?
0 notes
Text
How to Use SQL for Data Science Effectively
Start with the Right Training
If you're looking for the best data science training in Hyderabad, one of the first tools you should master is SQL. Structured Query Language (SQL) is fundamental to data analysis and a must-have skill for any aspiring data scientist.You can retrieve, filter, and manipulate data from relational databases with precision and speed.
Master the Basics and Go Beyond
To use SQL effectively, begin with the basics: SELECT statements, WHERE filters, JOINs, GROUP BY, and aggregate functions. These commands form the foundation for exploring and analyzing datasets. As you progress, dive into advanced topics like subqueries, common table expressions (CTEs), and window functions, which allow for more complex data transformations and analyses.
Integrate SQL with Data Science Tools
SQL pairs seamlessly with popular data science environments like Python and R. Tools such as Jupyter Notebooks allow you to run SQL queries alongside your code, creating a smooth workflow for data exploration, cleaning, and visualization. By integrating SQL with other tools, you can streamline your analysis process and enhance your productivity.
Build Scalable and Reproducible Workflows
One of the biggest advantages of using SQL in data science is its ability to support clean and reproducible workflows. SQL queries help document your data processing steps clearly, making it easier to collaborate with team members or revisit your analysis in the future.
Conclusion
Learning SQL is essential for anyone serious about a career in data science. It not only improves your ability to handle and analyze data but also strengthens your overall technical foundation. For structured learning and hands-on experience, consider enrolling at SSSiIT Computer Education, where expert-led training will prepare you for real-world data science challenges.
#best software training in hyderabad#best data science training in hyderabad#best data science training in kphb
0 notes
Text
Common Table Expressions (CTEs) in ARSQL Language
Mastering Common Table Expressions (CTEs) in ARSQL Language: A Complete Guide Hello, Redshift and ARSQL enthusiasts! In this post, we’re diving into Common Table Expressions in ARSQL-one of the most powerful and flexible features in SQL Common Table Expressions (CTEs) in the ARSQL Language. Whether you’re simplifying complex queries, improving code readability, or handling recursive data…
0 notes
Text
Advanced Database Design

As applications grow in size and complexity, the design of their underlying databases becomes critical for performance, scalability, and maintainability. Advanced database design goes beyond basic tables and relationships—it involves deep understanding of normalization, indexing, data modeling, and optimization strategies.
1. Data Modeling Techniques
Advanced design starts with a well-thought-out data model. Common modeling approaches include:
Entity-Relationship (ER) Model: Useful for designing relational databases.
Object-Oriented Model: Ideal when working with object-relational databases.
Star and Snowflake Schemas: Used in data warehouses for efficient querying.
2. Normalization and Denormalization
Normalization: The process of organizing data to reduce redundancy and improve integrity (up to 3NF or BCNF).
Denormalization: In some cases, duplicating data improves read performance in analytical systems.
3. Indexing Strategies
Indexes are essential for query performance. Common types include:
B-Tree Index: Standard index type in most databases.
Hash Index: Good for equality comparisons.
Composite Index: Combines multiple columns for multi-column searches.
Full-Text Index: Optimized for text search operations.
4. Partitioning and Sharding
Partitioning: Splits a large table into smaller, manageable pieces (horizontal or vertical).
Sharding: Distributes database across multiple machines for scalability.
5. Advanced SQL Techniques
Common Table Expressions (CTEs): Temporary result sets for organizing complex queries.
Window Functions: Perform calculations across a set of table rows related to the current row.
Stored Procedures & Triggers: Automate tasks and enforce business logic at the database level.
6. Data Integrity and Constraints
Primary and Foreign Keys: Enforce relational integrity.
CHECK Constraints: Validate data against specific rules.
Unique Constraints: Ensure column values are not duplicated.
7. Security and Access Control
Security is crucial in database design. Best practices include:
Implementing role-based access control (RBAC).
Encrypting sensitive data both at rest and in transit.
Using parameterized queries to prevent SQL injection.
8. Backup and Recovery Planning
Design your database with disaster recovery in mind:
Automate daily backups.
Test recovery procedures regularly.
Use replication for high availability.
9. Monitoring and Optimization
Tools like pgAdmin (PostgreSQL), MySQL Workbench, and MongoDB Compass help in identifying bottlenecks and optimizing performance.
10. Choosing the Right Database System
Relational: MySQL, PostgreSQL, Oracle (ideal for structured data and ACID compliance).
NoSQL: MongoDB, Cassandra, CouchDB (great for scalability and unstructured data).
NewSQL: CockroachDB, Google Spanner (combines NoSQL scalability with relational features).
Conclusion
Advanced database design is a balancing act between normalization, performance, and scalability. By applying best practices and modern tools, developers can ensure that their systems are robust, efficient, and ready to handle growing data demands. Whether you’re designing a high-traffic e-commerce app or a complex analytics engine, investing time in proper database architecture pays off in the long run.
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
Unlock SQL CTE Power
Unleashing the Power of Common Table Expressions (CTEs) in SQL 1. Introduction Common Table Expressions (CTEs) are a powerful feature in SQL that allow you to simplify complex queries by temporarily storing the result of a SELECT statement, which can then be referenced within a SELECT, INSERT, UPDATE, or DELETE statement. CTEs are particularly useful for breaking down complex queries into more…
0 notes
Text
蜘蛛池搭建需要哪些SQL技术?
在互联网世界中,蜘蛛池(Spider Pool)是一种用于自动化抓取和处理网页数据的技术。它通过模拟多个浏览器请求来提高爬虫的效率和稳定性。在构建蜘蛛池的过程中,SQL技术扮演着至关重要的角色。本文将深入探讨在搭建蜘蛛池时需要用到的SQL技术。
1. 数据库设计与优化
首先,一个高效的蜘蛛池离不开良好的数据库设计。这包括合理规划表结构、索引以及存储过程等。例如,在设计URL表时,可以考虑使用哈希函数对URL进行预处理,以减少重复抓取的可能性。此外,还需要根据业务需求选择合适的数据库类型,如关系型数据库MySQL或非关系型数据库MongoDB。
2. SQL查询优化
在蜘蛛池运行过程中,频繁地从数据库中读取和写入数据是不可避免的。因此,如何编写高效的SQL查询语句就显得尤为重要了。可以通过以下几种方式来优化SQL查询:
- 使用JOIN操作代替子查询
- 避免全表扫描,尽量利用索引来提高查询速度
- 合理使用GROUP BY和HAVING子句
- 减少不必要的字段选择
3. 数据清洗与处理
在抓取到大量数据后,往往需要对其进行清洗和处理才能更好地利用这些信息。这里就需要用到一些高级的SQL技巧了,比如窗口函数、CTE(Common Table Expressions)等。这些工具可以帮助我们快速完成复杂的计算任务,并且保持代码的简洁性。
4. 数据同步与备份
为了保证数据的安全性和一致性,定期进行数据同步和备份也是非常必要的。这通常涉及到触发器、事务管理等方面的知识。同时,在多节点部署的情况下,还需要考虑分布式事务的问题。
5. 性能监控与调优
最后,对于任何系统来说,性能监控都是不可或缺的一部分。通过分析SQL执行计划、等待事件等指标,我们可以找出瓶颈所在并采取相应措施进行优化。此外,还可以利用缓存机制来进一步提升系统的响应速度。
总之,在搭建蜘蛛池时,掌握好以上这些SQL技术将会极大地提高整个项目的成功率。当然,除了SQL之外,还有许多其他方面的知识也需要学习和掌握。希望本文能够对你有所帮助!
你认为在搭建蜘蛛池时,最重要的SQL技术是什么?欢迎在评论区分享你的看法!
加飞机@yuantou2048

Google外链购买
谷歌留痕
0 notes
Text
Senior Data Analyst - Python Developer with SQL
with Python programing based development 4+ years of experience in relational databases (SQL Query, Stored Procedure. CTE… Apply Now
0 notes
Text
Senior Data Analyst - Python Developer with SQL
with Python programing based development 4+ years of experience in relational databases (SQL Query, Stored Procedure. CTE… Apply Now
0 notes
Text
CTEs are the greatest thing sql ever came up with
#don't mind me having a moment#I FEEL SO POWERFUL!#anyway I wrote a 200 line query today. how was yalls day
0 notes
Text
SQL Techniques for Handling Large-Scale ETL Workflows
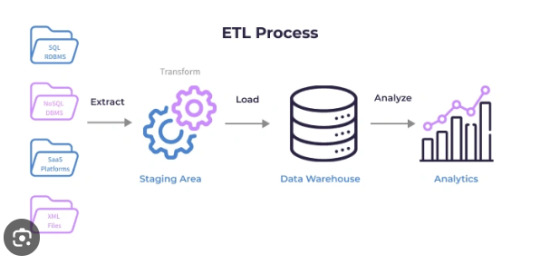
Managing and analyzing large datasets has become a critical task for modern organizations. Extract, Transform, Load (ETL) workflows are essential for moving and transforming data from multiple sources into a centralized repository, such as a data warehouse. When working with large-scale datasets, efficiency, scalability, and performance optimization are crucial. SQL, a powerful language for managing relational databases, is a core component of ETL workflows. This article explores SQL techniques for effectively handling large-scale Extract Transform Load SQL workflows.
Understanding the ETL Process
ETL workflows consist of three key stages:
Extract: Retrieving data from various sources, such as databases, APIs, or files.
Transform: Applying business logic to clean, validate, and format the data for analysis.
Load: Inserting or updating the processed data into a target database or data warehouse.
SQL is widely used in ETL processes for its ability to handle complex data transformations and interact with large datasets efficiently.
Challenges of Large-Scale ETL Workflows
Large-scale ETL workflows often deal with massive data volumes, multiple data sources, and intricate transformations. Key challenges include:
Performance Bottlenecks: Slow query execution due to large data volumes.
Data Quality Issues: Inconsistent or incomplete data requiring extensive cleaning.
Complex Transformations: Handling intricate logic across disparate datasets.
Scalability: Ensuring the workflow can handle increasing data volumes over time.
SQL Techniques for Large-Scale ETL Workflows
To address these challenges, the following SQL techniques can be employed:
1. Efficient Data Extraction
Partitioned Extraction: When extracting data from large tables, use SQL partitioning techniques to divide data into smaller chunks. For example, query data based on date ranges or specific IDs to minimize load on the source system.
Incremental Extraction: Retrieve only the newly added or updated records using timestamp columns or unique identifiers. This reduces the data volume and speeds up the process.
2. Optimized Data Transformation
Using Window Functions: SQL window functions like ROW_NUMBER, RANK, and SUM are efficient for complex aggregations and calculations. They eliminate the need for multiple joins and subqueries.
Temporary Tables and CTEs: Use Common Table Expressions (CTEs) and temporary tables to break down complex transformations into manageable steps. This improves readability and execution performance.
Avoiding Nested Queries: Replace deeply nested queries with joins or CTEs for better execution plans and faster processing.
3. Bulk Data Loading
Batch Inserts: Load data in batches instead of row-by-row to improve performance. SQL’s INSERT INTO or COPY commands can handle large data volumes efficiently.
Disable Indexes and Constraints Temporarily: When loading large datasets, temporarily disabling indexes and constraints can speed up the process. Re-enable them after the data is loaded.
4. Performance Optimization
Indexing: Create appropriate indexes on columns used in filtering and joining to speed up query execution.
Query Optimization: Use EXPLAIN or EXPLAIN PLAN statements to analyze and optimize SQL queries. This helps identify bottlenecks in query execution.
Partitioning: Partition large tables based on frequently queried columns, such as dates or categories. Partitioning allows SQL engines to process smaller data chunks efficiently.
5. Data Quality and Validation
Data Profiling: Use SQL queries to analyze data patterns, identify inconsistencies, and address quality issues before loading.
Validation Rules: Implement validation rules during the transformation stage to ensure data integrity. For example, use CASE statements or conditional logic to handle null values and invalid data.
6. Parallel Processing
Parallel Queries: Many modern SQL databases support parallel query execution, enabling faster data processing for large workloads.
Divide and Conquer: Divide large datasets into smaller subsets and process them in parallel using SQL scripts or database-specific tools.
Best Practices for Large-Scale ETL Workflows
Use Dedicated ETL Tools with SQL Integration: Tools like Apache Spark, Talend, and Informatica can handle complex ETL workflows while leveraging SQL for transformations.
Monitor and Optimize Performance: Regularly monitor query performance and optimize SQL scripts to handle growing data volumes.
Automate and Schedule ETL Processes: Use schedulers like cron jobs or workflow orchestration tools such as Apache Airflow to automate SQL-based ETL tasks.
Document and Version Control SQL Scripts: Maintain detailed documentation and version control for SQL scripts to ensure transparency and ease of debugging.
Advantages of SQL in Large-Scale ETL Workflows
Scalability: SQL is highly scalable, capable of handling petabytes of data in modern database systems.
Flexibility: Its ability to work with structured data and perform complex transformations makes it a preferred choice for ETL tasks.
Compatibility: SQL is compatible with most databases and data warehouses, ensuring seamless integration across platforms.
Conclusion
Handling large-scale Extract Transform Load SQL workflows requires a combination of efficient techniques, performance optimization, and adherence to best practices. By leveraging SQL’s powerful capabilities for data extraction, transformation, and loading, organizations can process massive datasets effectively while ensuring data quality and consistency.
As data volumes grow and workflows become more complex, adopting these SQL techniques will enable businesses to stay ahead, making informed decisions based on accurate and timely data. Whether you are managing enterprise-scale data or integrating multiple data sources, SQL remains an indispensable tool for building robust and scalable ETL pipelines.
0 notes
Text
Recursive Common Table Expressions (CTE) in T-SQL
Mastering Recursive Common Table Expressions (CTE) in T-SQL Hello, fellow SQL enthusiasts! In this blog post, I will introduce you to Recursive Common Table Expressions in T-SQL – one of the most powerful and flexible features in T-SQL: Recursive Common Table Expressions (CTE). Recursive CTEs allow you to perform iterative operations by referencing themselves, making it easier to work with…
0 notes